
IT Log
07. 통계적 추론(Statistical Inference) 본문
1. 추정
ㅇㄴㄹㄴ
2. 가설검정
ㄴㅇㄹㄴㅇㄹ
통계적 추론이란?
표본들로부터 모집단에 대해 추론하는 과정을 말하며 '추정 통계학'이라고도 불립니다. 추출된 표본으로부터 특성을 분석하여 모집단의 특성을 추론합니다. 모집단 특성에는 모평균, 모분산, 모표준편차 등이 있습니다.
통계적 추론 구분
통계적 추정
모집단에서 추출한 표본 특성을 분석하여, 모수의 특성을 추정하는 것
가설검정
모집단 실제의 값이 얼마가 된다는 주장과 관련해, 표본의 정보를 사용해서 가설의 합당성 여부를 판정하는 과정을 의미
가설검정 절차
- 귀무가설과 대립가설을 설정, 유의 수준 설정(일반적으로 0.05 또는 0.01)
- 검정 통계량 설정 (Z 분포, t 분포, 카이제곱 분포, F 분포 등)
- 분포에 따른 임계치, 기각역 설정
- 검정 통계량 계산
- 통계적인 의사결정(귀무가설 기각 여부) 및 결론
통계적 추론 방법
모수적 방법
모집단의 분포 형태는 알고 있으나, 모수는 모르는 경우 모수를 추론
비모수적 방법
모집단의 분포 형태도 알 수 없는 경우, 모집단의 분포함수 및 모수를 추론
모델링 가정
- 완전모수 : 데이터 생성 과정을 설명하는 확률 분포는 한정된 수의 알려지지 않은 매개 변수만 포함하는 확률 분포 계열에 의해 완전히 설명된 것으로 가정합니다. 예를 들어 모집단 값의 분포가 평균과 분산을 알 수 없는 정규분포라고 가정하고 간단한 랜덤 샘플링으로 데이터세트를 생성합니다.
- 비모수 : 데이터를 생성하는 프로세스에 대한 가정은 모수 통계보다 훨씬 작으며 최소일 수 있습니다. 예를 들어 모든 연속 확률 분포에는 중앙값이 있으며, 이 중앙값은 표본 중앙값 또는 추정기를 사용하여 추정할 수 있으며 데이터가 간단한 랜덤 샘플링에서 발생하는 경우 좋은 특성을 갖습니다.
- 반모수 : 완전모수와 비모수 접근 방식 사이의 가정을 의미합니다. 예를 들어, 인구 분포가 유한 평균이라고 가정할 수 있습니다. 또한 모집단의 평균 반응 수준이 일부 공변량 (모수적 가정)에 따라 실제로 선형 방식에 의존하지만 그 평균 주변의 변동을 설명하는 모수적 가정을 만들지 않는다고 가정할 수 있습니다. 보다 일반적으로, 반모수적 모델은 종종 '구조적'및 '무작위 변형' 구성 요소로 분리될 수 있습니다. 한 구성 요소는 모수적으로 처리되고 다른 구성 요소는 비모수적으로 처리됩니다. 잘 알려진 Cox 모델은 일련의 반모수적 가정입니다.
가정의 중요성
어떤 수준의 가정이 이루어지든, 일반적으로 올바른 추론은 가정이 정확해야 합니다. 간단한 랜덤 샘플링의 잘못된 가정은 통계적 추론을 무효화할 수 있습니다. 정규분포는 어떤 종류의 모집단을 다루고 있다면 완전히 비현실적이고 치명적인 현명한 가정이 될 것 입니다? 여기서, 중심극한정리는 표본 평균의 분포가 대략적으로 정규분포를 나타냅니다?
가설 검정
모집단 실제의 값이 얼마가 된다는 가설을 표본의 정보를 사용하여 합당성 여부를 판정하는 과정입니다. 일반적으로 두 개의 데이터 세트를 비교하거나 Sampling을 통해 얻은 데이터 세트를 이상적인 모델의 합성 데이터 세트와 비교합니다.
Z-test
귀무 가설에서 테스트 통계량의 분포를 정규 분포(Z분포)로 근사할 수 있는 통계 검정으로, 모집단의 분산을 이미 알고 있는 분포의 평균을 테스트합니다.
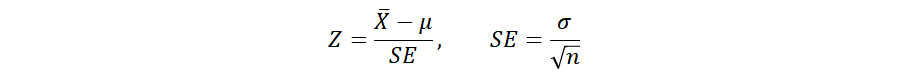
여기서 SE는 표본평균집단의 표준편차이기도 합니다.
T-test
귀무 가설에서 검정하는 통계량이 t-분포를 따르는 통계적 가설 검정입니다. 통계량이 정규 분포를 따르는 경우에 가장 일반적으로 적용되며, 모집단의 분산을 모르거나 이를 추정값으로 대체하면 특정 조건하에서 t-분포를 따릅니다.

Z-test로 T-test 값을 추정할 수도 있습니다.
T-분포
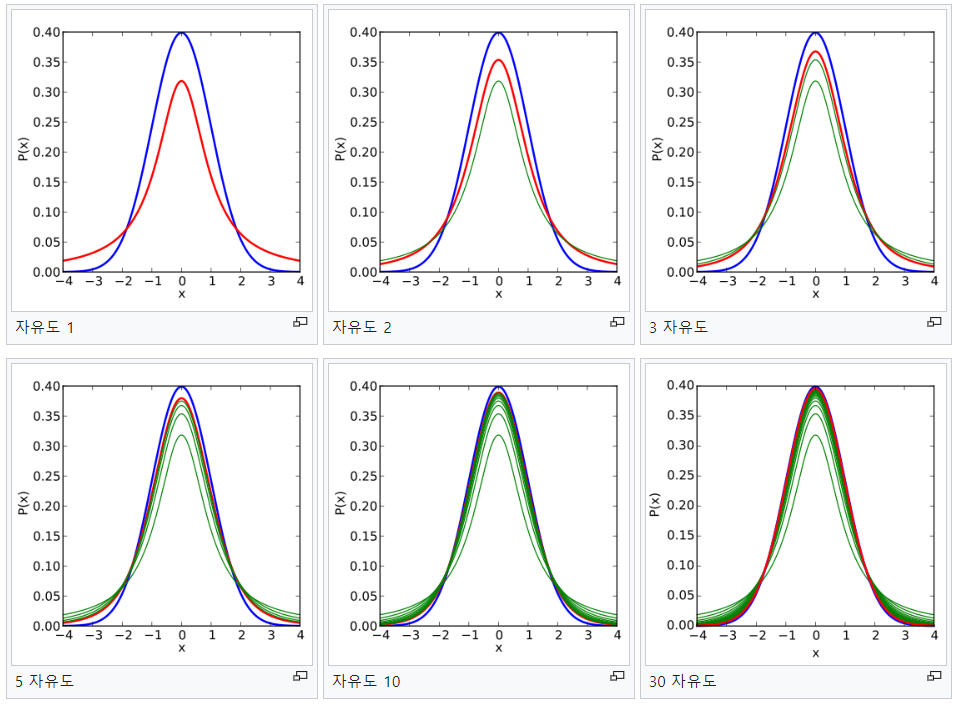
자유도 : 모수의 추정치에 들어가는 독립적인 정보의 수
확률분포에서의 자유도(v)는 표본집단의 평균과 분산에서 각각 n과 n-1입니다.

위의 그림에서 파란색 선은 표준정규분포로 자유도가 30일 때, t-분포가 표준정규분포와 거의 근사하는 것으로 나타납니다. 따라서, 표본크기 n은 30이상일 때 통계적으로 이용하기 좋다고 볼 수 있습니다.
귀무가설
귀무가설은 통계학에서 처음부터 버릴 것을 예상하는 가설로, 의미있는 차이가 없는 경우의 가설입니다.
1종오류 : 가설이 참이어도 기각하는 경우
2종오류 : 가설이 거짓이어도 기각하지 않는 경우
ex) 귀무가설 : 남자 평균키는 173cm 이다.
대립가설 : 남자 평균키는 173cm가 아니다.
대립가설
귀무가설에 대립하는 가설로 어떤 가능성에 대해 확률적인 가설 검정을 할 때 귀무가설과 함께 사용하며, 검증을 직접 수행하는 것은 불가능하나 귀무가설을 기각하는 반증의 과정을 거쳐 받아들여집니다.
단측 대립 가설 : 독립변수와 결과 변수와의 관련성을 검정할 떄 그 방향이 미리 어느 한쪽으로 결정되어 있는 경우 ( >, < )
양측 대립 가설 : 독립변수와 결과 변수간에 관련성 혹은 차이가 존재하는가?라는 면에서 방향은 따지지 않는 경우 ( ≠ )
ex) 기존의 약에 비하여 신약이 더 효과가 좋은가? → 단측 대립 가설
ex) 기존의 약과 신약의 효과를 비교하면 효과에 차이가 있는가? → 양측 대립 가설
귀무가설과 대립가설 설정
한국 성인 여성의 평균 키는 170cm라는 가설을 검정한다면, 귀무가설은

이에 대한 대립가설은 아래와 같다

p-value
귀무가설이 맞다는 가정하에 표본에서 실제로 관측된 통계치가 같거나 더 극단적인 통계치가 관측될 확률로 0~1사이 값으로 나타냅니다. 일반적으로 p-value가 유의수준 0.05나 0.01보다 작은 경우 귀무가설을 기각합니다. p-value는 귀무 가설의 기각 여부를 결정하기 위한 도구일 뿐이지 가설을 증명하지 않습니다.
유의수준
유의 수준은 α로 표시하며, 귀무가설을 기각할지 아니면 유지해야하는지 여부를 결정합니다. 일반적으로 5%이하로 설정합니다.

p-vavlue가 유의수준과 같거나 크면 귀무가설을 채택하고, 그렇지 않으면 대립가설을 채택합니다.
신뢰 구간
표본집단에서 관측한 데이터로 모집단의 변수에 대한 값의 범위를 제안합니다. 그리고 실제 모집단의 변수가 제안된 범위 안에 있다는 신뢰수준이 있습니다. 신뢰수준은 조사자가 선택할 수 있습니다. 신뢰수준은 모집단의 실제 값을 포함하는 신뢰구간의 빈도(비율)을 나타냅니다. 신뢰수준은 데이터를 검증하기 전에 지정합니다. 일반적으로 95% 신뢰수준이 사용되며, 90%나 99%는 종종 분석에 사용됩니다.
신뢰구간의 너비는 표본의 크기와 신뢰수준이나 표본의 변동성에 의해 영향을 받습니다. 다른 요인이 모두 같다고 가정할 때 표본의 크기가 클수록 변수를 추정하는 정도가 높으며 신뢰수준이 높을수록 신뢰구간이 넓어집니다.
- 신뢰수준이 95%라는 것은 표본집단의 95%가 신뢰 구간내에 있다는 것이 아님
- 신뢰구간은 모집단에 대한 그럴듯한 값의 추정치
신뢰구간을 계산하는 절차
- 표본평균을 구한뒤 모집단의 표준편차를 아는 경우 100(1-α)%
- 모집단의 표준편차를 모르는 경우 t-분포 값을 사용(표본크기가 30미만이고 표준편차를 모르는 경우)

ex) '한국인의 평균 키는 170이다'라는 귀무가설을 세웠고, 모집단의 표준편차가 2이고, 표본평균은 171, 유의 수준은 0.05, 신뢰수준은 95% 설정했습니다. 그렇다면 표본평균과 모집단의 표준편차를 알고 있고, 유의수준은 0.05이므로 신뢰구간은 계산식에 의해서 95%가 됩니다. 95%는 초록색 선과 비슷하므로 평균에서 2σ를 더하고 뺸 171-2 ~ 171+2로 169~173 사이의 모집단의 평균이 있을거라고 95% 신뢰수준으로 추정합니다. 그런데 이 때 관측값이 169와 173사이 값이 아닌 176이라는 값이 나왔다면 이는 유의수준이 0.05보다 낮은 유의 확률의 값으로 귀무가설을 기각하게 되어 '한국인의 평균 키는 170이 아니다'라는 대립가설을 주장할 수 있습니다.
p-hacking
p-value를 원하는 값으로 얻어내는 일로 최종적인 p-value가 아닌 p-value를 구하는 과정에서 데이터를 선별해서 사용하는 것을 말합니다. 일반적으로 선택하는 유의수준 값인 0.05 전후로 p-value가 급격하게 차이나는 현상이 경제, 물리, 생물 등 다양한 분야에서 나타나고 있습니다.
T-test란?
검정하는 통계량이 귀무가설에서 t-분포를 따르는 통계적 가설 검정으로, 단일 표본에서 얻은 평균이 모집단의 평균과 같은 값을 갖는지 알아보는 One Sample T-test와 두 모집단의 평균의 차이를 알아보는 Two Sample T-test가 있습니다.
가정
- 정규 분포를 따를 것
- 독립적인 집단일 것
- ㅇㄴㄹㄴ
- ㄹㄴㅇ
- ㄹ
One Sample T-test
모집단 평균이 지정된 표본의 평균값과 같다는 귀무가설을 검정할 때 통계량을 사용합니다.

One Sample T-test 검정통계량
표본의 평균 x ̅, 모집단 평균 μ, 표본의 표준편차 s, 표본의 크기 n
Two Sample T-test
1. 독립적인 Samples <Independent (unpaired) samples>
- 동일한 표본 크기 및 분산인 경우
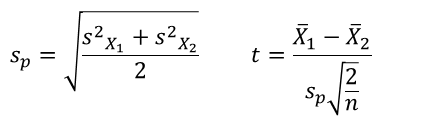
t의 분모는 두 평균의 차이에 대한 표준 오차, n은 각 그룹에 참가자 수, 자유도는 2n-2
- 표본 크기가 같거나 같지 않고 분산이 동일한 경우

n은 표본 크기, 모집단 평균이 같은지 여부
- 동일하지 않은 표본 크기와 분산인 경우

n은 표본크기 s는 표준편차
2. 쌍을 이룬 Samples <Paired samples>

차이의 평균이 유의하게 다른지 테스트하는 경우 모평균은 0, 사용된 자유도는 n-1, 여기서 n은 쌍의 수
두번 테스트된 Sample이 하나만 있는 경우나 pairing된 Sample이 두 개 있는 경우입니다.
T-test
귀무 가설에서 검정하는 통계량이 t-분포를 따르는 통계적 가설 검정입니다. 통계량이 정규 분포를 따르는 경우에 가장 일반적으로 적용되며, 모집단의 분산을 모르거나 이를 추정값으로 대체하면 특정 조건하에서 t-분포를 따릅니다.

Z-test로 T-test 값을 추정할 수도 있습니다.
T-분포

자유도 : 모수의 추정치에 들어가는 독립적인 정보의 수
확률분포에서의 자유도(v)는 표본집단의 평균과 분산에서 각각 n과 n-1입니다.

위의 그림에서 파란색 선은 표준정규분포로 자유도가 30일 때, t-분포가 표준정규분포와 거의 근사하는 것으로 나타납니다. 따라서, 표본크기 n은 30이상일 때 통계적으로 이용하기 좋다고 볼 수 있습니다.
One Sample T-test
'Statistics > 통계(Statistics)' 카테고리의 다른 글
| 06. 기술 통계(Descriptive Statistics) (0) | 2020.08.18 |
|---|---|
| 05. 모집단과 표본(Population and Sample) (0) | 2020.08.18 |
| 04. 확률 분포(Probability Distribution) (0) | 2020.08.18 |
| 03. 확률 (Probability) (0) | 2020.08.18 |
| 02. 통계의 자료(Statistics Data) (0) | 2020.08.18 |



