
IT Log
Spark 설치 본문
- 요구사항
- Spark 설치
- 환경변수 설정
- Standalone
- Spark 배포
- Slaves
- 웹 UI 확인
- Spark Shell
요구사항
- Java 1.8 이상
- Hadoop 2.7.x 이상
Spark 설치
wget http://apache.mirror.cdnetworks.com/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
tar xzvf spark-2.4.3-bin-hadoop2.7.tgz
mv spark-2.4.3-bin-hadoop2.7 spark
위 코드를 실행하여 Spark를 설치하고 폴더명을 간단하게 수정합니다.
환경변수 설정
export JAVA_HOME=/usr/local/jdk1.8.0_211
export HADOOP_HOME=/usr/local/hadoop-2.9.2
export MAVEN_HOME=/usr/local/maven
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$MAVEN_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:
/etc/profile에 HOME과 PATH를 설정합니다.
Standalone


start-master.sh코드로 Master를 실행시킨후 웹을 실행하여 master:8080을 입력하면 화면과 같이 웹 UI를 볼 수 있습니다. 보시면 Workers에 0으로 아무것도 존재하지 않으니 한 번 추가를 해보겠습니다. (URL을 기억해 둡시다.)
Spark 배포
scp -r /usr/local/spark root@slave1:/usr/local/
scp -r /usr/local/spark root@slave2:/usr/local/
scp -r /usr/local/spark root@slave3:/usr/local/slave1, slave2, slave3노드에 spark 폴더를 배포해줍니다. 그리고 master노드와 같이 환경변수 설정을 해줍니다.
Slaves

slave1
slave2
slave3
/usr/local/spark/conf 로 이동합니다. mv slaves.template slaves 로 slaves 파일을 생성합니다. 그리고 slaves 파일에 위 코드를 추가합니다.
Worker 실행

start-slave.sh spark://master:7077
slave1, slave2, slave3에서 위 코드를 모두 실행해 줍니다. spark://master:7077은 <master-spark-URL>로 master를 실행시키고 확인한 웹UI에서 URL을 확인하면 알 수 있습니다.
웹 UI 확인
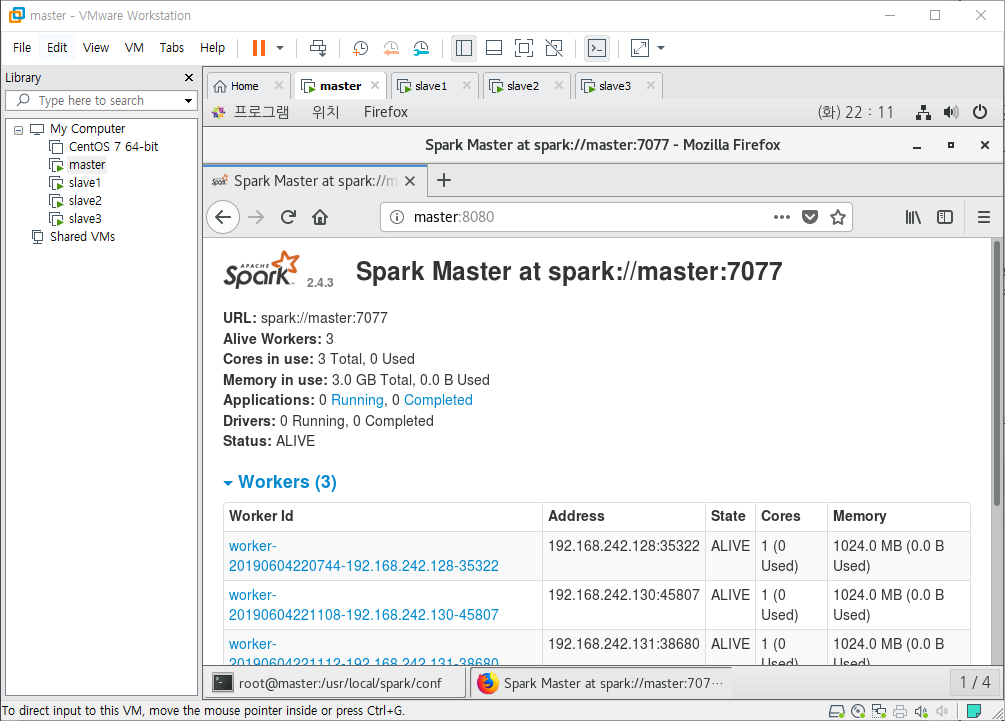
아까 실행했던 웹 UI를 새로고침 해보면 Workers가 추가된 걸 볼 수 있습니다.
Spark Shell


spark-shell --master spark://master:7077위 코드로 shell을 사용할 수 있고 웹 UI를 새로고침으로 다시 확인해 보면 Running Applications 목록에 추가가 된걸 보실 수 있습니다. 다른 노드에서도 위 코드를 입력하여 실행할 수 있습니다. 그리고 실행한 shell 하나를 종료하면 Completed Applications 목록에 추가된 걸 확인할 수 있습니다.
'Open Source > Apache' 카테고리의 다른 글
| Kafka 설치(1) (0) | 2019.06.09 |
|---|---|
| Pig 설치 (0) | 2019.06.09 |
| Maven 설치 (0) | 2019.06.04 |
| Hadoop 완전분산모드(6) (0) | 2019.06.02 |
| Hadoop 완전분산모드(5) (0) | 2019.05.31 |



